 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-evaluation of comparability metrics using parallel corpora
Apr 14, 2014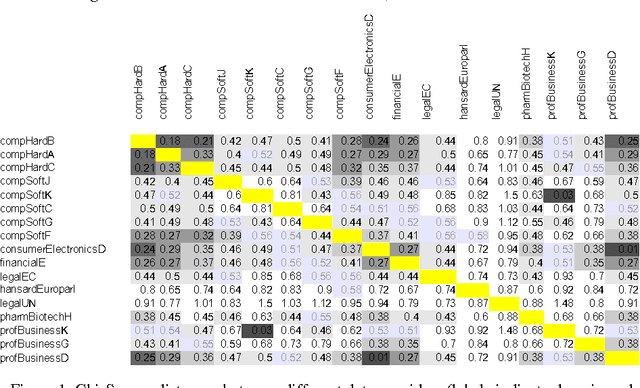


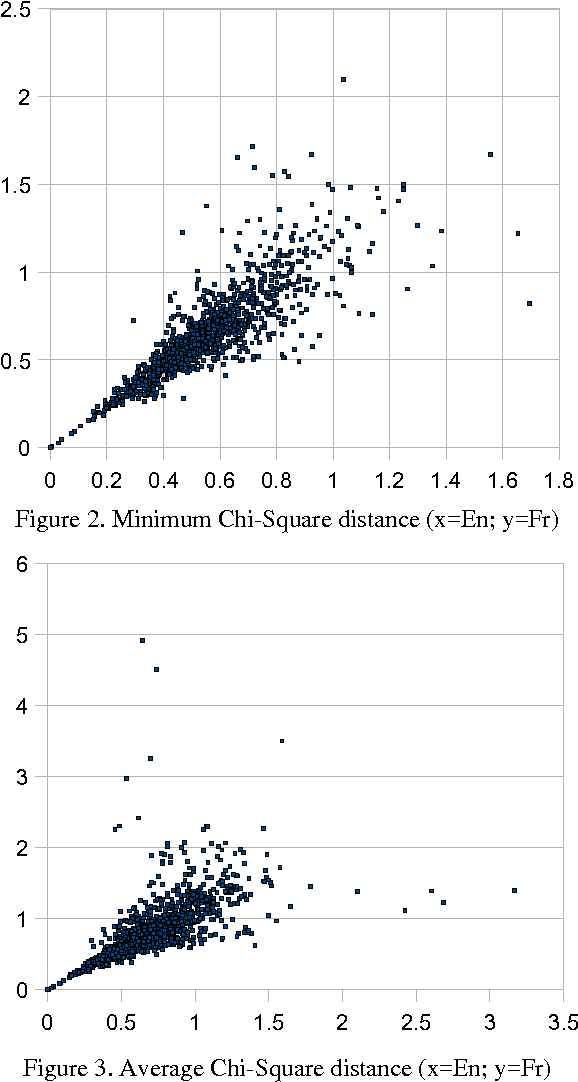
Metrics for measuring the comparability of corpora or texts need to be developed and evaluated systematically. Applications based on a corpus, such as training Statistical MT systems in specialised narrow domains, require finding a reasonable balance between the size of the corpus and its consistency, with controlled and benchmarked levels of comparability for any newly added sections. In this article we propose a method that can meta-evaluate comparability metrics by calculating monolingual comparability scores separately on the 'source' and 'target' sides of parallel corpora. The range of scores on the source side is then correlated (using Pearson's r coefficient) with the range of 'target' scores; the higher the correlation - the more reliable is the metric. The intuition is that a good metric should yield the same distance between different domains in different languages. Our method gives consistent results for the same metrics on different data sets, which indicates that it is reliable and can be used for metric comparison or for optimising settings of parametrised metrics.
Two Sources of Control over the Generation of Software Instructions
Jun 19, 1996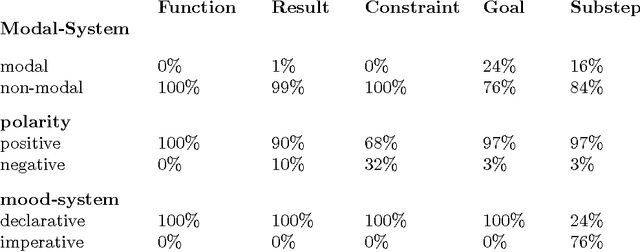


This paper presents an analysis conducted on a corpus of software instructions in French in order to establish whether task structure elements (the procedural representation of the users' tasks) are alone sufficient to control the grammatical resources of a text generator. We show that the construct of genre provides a useful additional source of control enabling us to resolve undetermined cases.